Hand Coding Our Very Own Type Token Ratio Generator
ABOUT
Natural Language Processing is a branch of Artificial Intelligence where we aim to take text or speech in natural languages (i.e. English or Hindi) and convert them into computer manipulable format. We then use the converted data in various fields such as Analytics, Machine Translation, Part of Speech Tagging, Chatbots, Summarization etc. The possibilities of using natural languages to extract data and then quantify them is endless.
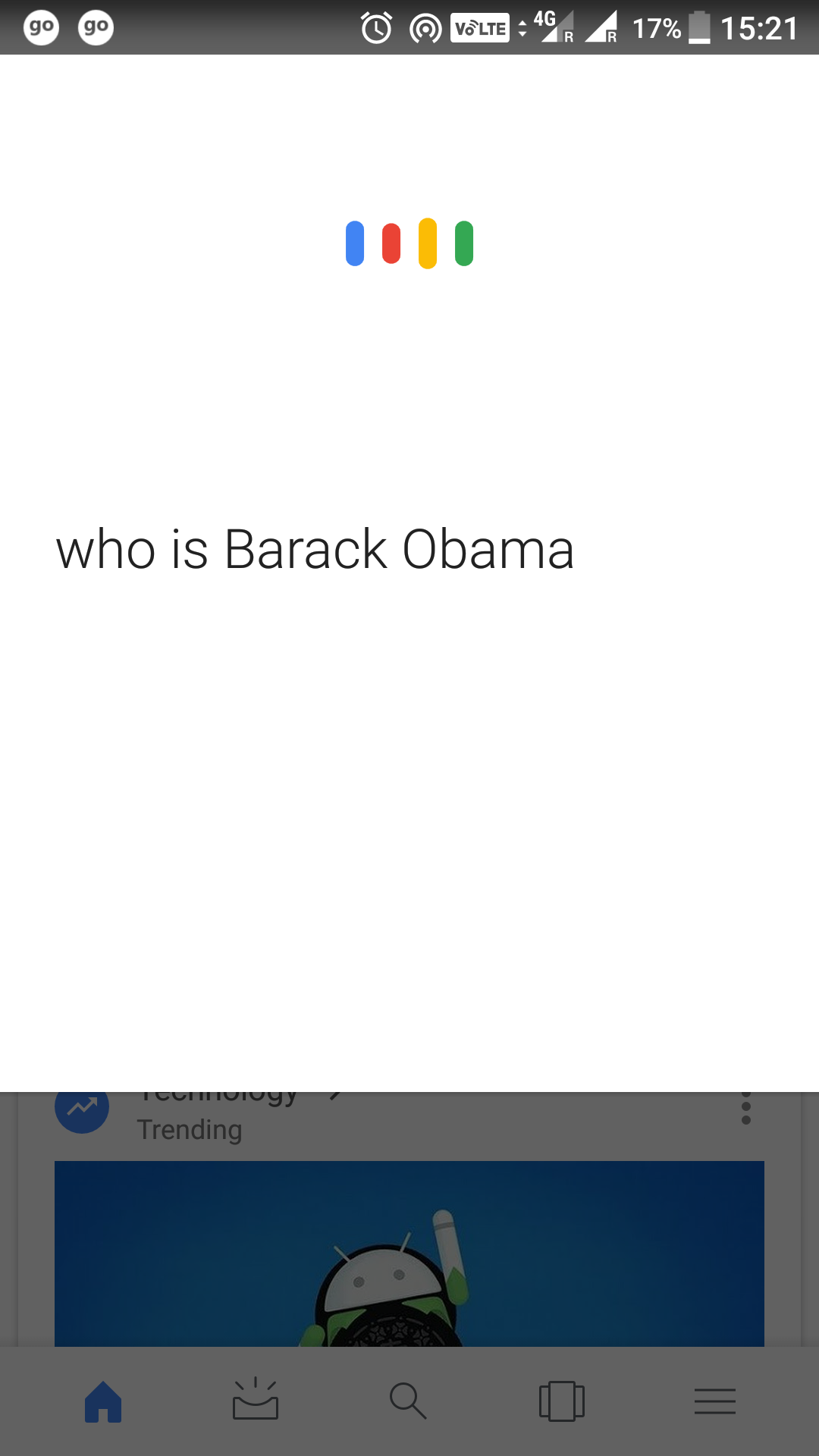
Let us take the example of using your Google Assistant.
When you ask it a question, such as “Who is Barrack Obama?”, it uses speech to text to convert your spoken words to text format.
The underlying system then splits the sentence into in to individual words or tokens in a process called tokenizing. You may then say, “Ok, Google, translate it into Hindi”. Google will then take each of these tokens and convert them to Hindi via a process called “Machine Translation”.
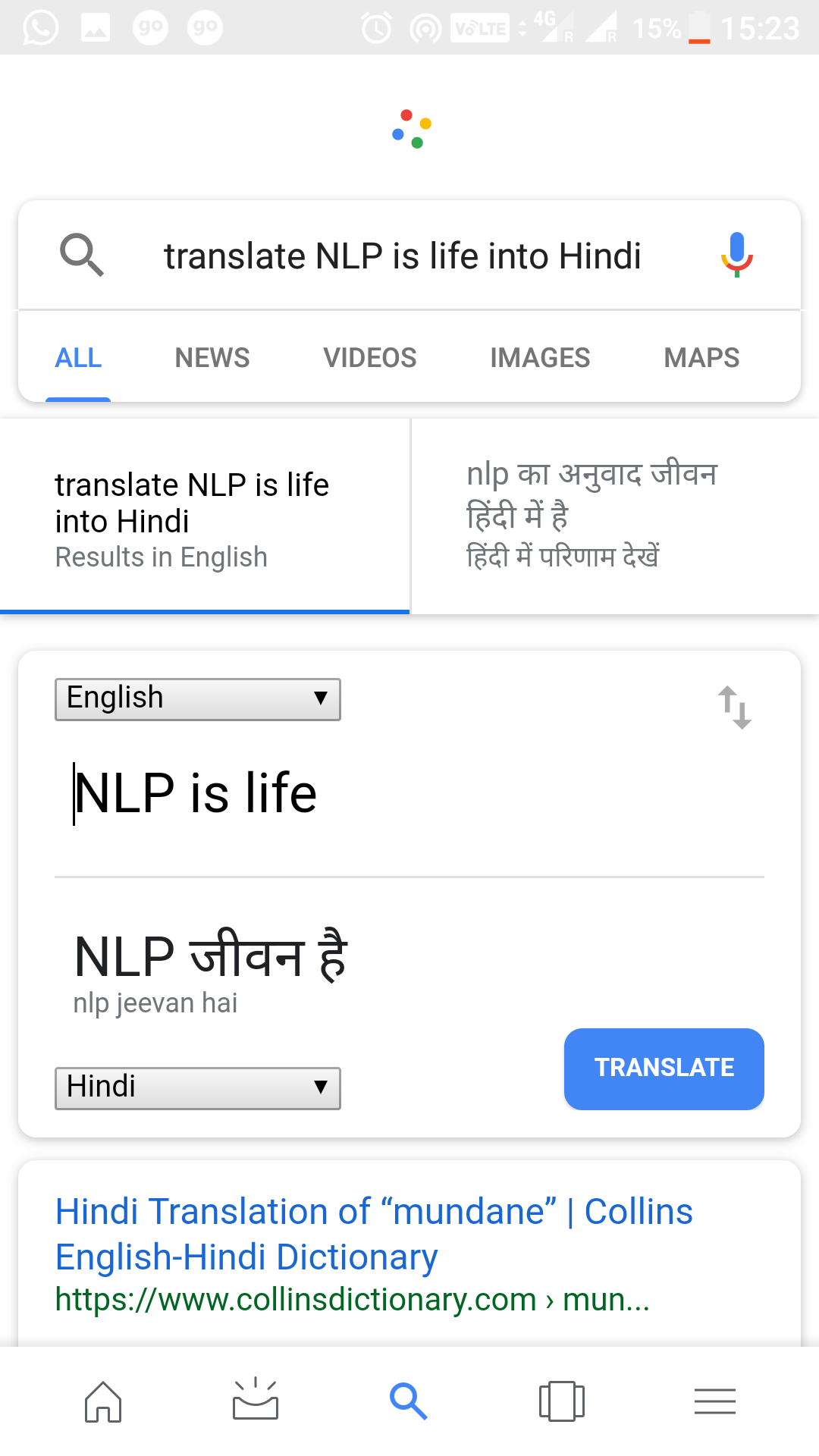
It will also check the converted words with the original sentence (i.e. “Who is Barack Obama”) and rearrange/convert the tenses of the translated words to ensure that translated sentence is grammatically correct. It might do this by recognizing the parts of speech using a “Parts of Speech Tagger”.
Finally, Google Assistant queries Wikipedia about “Barrack Obama” and then shows you the most important sentences in the Wikipedia article via a process called Summarization.
Although this is a very basic overview, it sure does help us understand how important NLP is and how it forms the underlying logic for some of the applications that we use daily.
Starting Out With Our First NLP Code
In this article we are going to do something really simple – we are going to write a simple Python script to find the TTR or the Type-Token Ratio of a paragraph of text and determine whether that text is of good quality or not.
*For any paragraph of text, the no. of types is the number of unique tokens (words) contained in that paragraph while the no. of tokens is the total number of words in that paragraph. *
TTR is a measure of the lexical diversity (and some say, hence quality) of a text. Which makes total logical sense right?
I mean the sentence: The red dog jumped over the red fox.
Type:6
Token: 8
TTR: 75%
Obviously has more meaning than: The the the the the the the the.
Type: 1
Token: 8
TTR: 12.5%
Although both of them have the same number of words. (We shall later learn about more comprehensive measures such as Flesch Reading Ease Score (FRES) or the Automated Readability Index (ARI)).
CODE
STEP 1:
We will have to import our dependencies.
For this script, we are using fantastic NLP library called NLTK.
To install NLTK in your terminal, simply type:
pip install nltk
We will then import nltk and regex by
import nltk as nlp
import re
STEP 2: Declare a string containing our string for which we need to calculate the TTR.
document="""NLP articles are fun. But they are awfully difficult to write. NLP is not difficult, but the articles, wow would awfully make you think of writing NLP Books!"""
STEP 3: Remove all special characters using this regex.
document= re.sub(r'[^\w]', ' ', document)
STEP 4: Convert Document to Lower Case
document=document.lower()
Tokenize the document to generate a list of words
tokens=nlp.word_tokenize(document)
STEP 5: Group the tokens and find the count value of each token and store in dict types.
types=nlp.Counter(tokens)
And finally, find the TTR by dividing the length of dict types by length of list tokens
TTR= (len(types)/len(tokens))*100
print(TTR)
And it is that simple! You can now use this simple measure to rank the quality of texts!
Here is a Challenge for You:
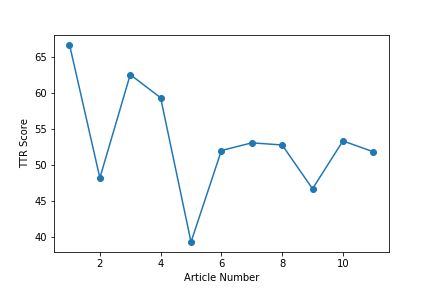
#####Download This Corpus (Collection Of Text Files) And Compare The TTR Values Of Each Text File And Plot Them On A Sentence_Rank Vs TTR Graph like this ->
You can find the solution here: https://github.com/RishavR/TTR-Generator